LMCS( luma mapping with chroma scaling)是 VVC 中新增的技术,其位 于去方块滤波之前,也被称为环路重整形(in-loop reshaper),主要包括两个部分:亮度映射(LM)、依赖亮度的色度缩放(CS)。
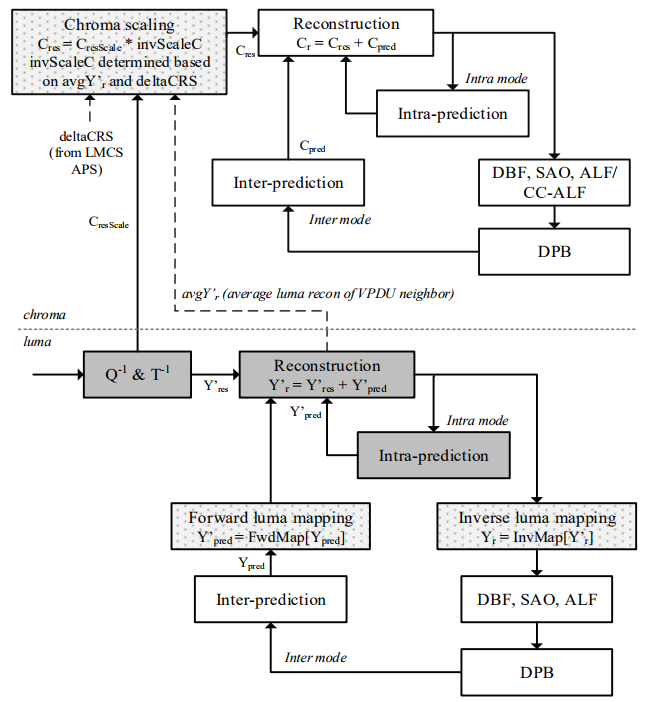
前向LM:将luma值从原始样本域映射到映射的样本域
反向LM:将luma值从映射的样本域映射回原始样本域
色度缩放:确定一个色度缩放因子并根据该缩放因子缩放色度残差值
映射样本域(灰色阴影块)中的过程包括反量化、反变换、luma帧内预测以及重建。原始采样域的过程包括环内滤波器、DPB 中参考图像存取和帧间预测。
LM
LM 在像素级进行操作,其基本思想是在给定位深下调整亮度值的取值范围, 这是因为一般的视频信号不会取完取值空间的所有值。例如 ITU-R BT.2100-2[5] 中对 10bit 视频的亮度窄范围取值为 64 到 940,更好地利用信号范围来提高编码效率。

解码端LM步骤
1.对解码出的luma变换系数进行反量化反变换产生【映射域】的亮度残差$Y’_{res}$
2.在【映射域】重建luma样本,$Y’_{r} = Y’_{res} + Y’_{pred}$
$Y’_{pred}$:帧内下,直接通过【映射域】的帧内预测得出;帧间下,首先使用解码缓冲区(DPB)的参考图像进行运动补偿后产生【原始样本域】的预测值$Y_{pred}$,然后进行前向LM产生映射域预测值$Y’_{pred}$。(帧间预测的运动补偿时在原始像素域进行,但是信号重建在映射域进行)
3.$Y’_{r}$进行反向LM,然后环路滤波。
FwdMap和InvMap
亮度映射为可逆过程,且分段进行,通过一个前向映射函数FwdMap实现,其对应的逆向映射函数为InvMap。
FwdMap是一个分段线性模型,参数需要在码流中传输,而InvMap不需要在码流中传输,解码器可以通过FwdMap生成InvMap函数。
分段线性模型使用两个输入点$InputPivot[]$和两个输出点$MappedPivot[]$来确定分段及该分段内的映射关系,用$SignalledCW[ i ]$表示第$i$段输出码字数量(编码端确定)。
输入分段InputPivot[]的确定:
输入分段固定划分为16个,每个分段码字数量用$OrgCW$表示。如对于10bit信号划分为16个分段,每个分段包含64个码字,$OrgCW = 64$。
$InputPivot[i]=i*OrgCW,i=0,1…16$,表示原始信号域每个分段的枢轴点。
输出分段MappedPivot[]:在编码过程中计算出映射域枢轴点MappedPivot[i]。
MappedPivot[ 0 ] = 0;
MappedPivot[i+1] = MappedPivot[i] + SignalledCW [i]
根据输入和输出分段即可确定当前段内的映射函数,即分段线性模型:
$Y_{pred}^{\prime}=\frac{\mathrm{MappedPivot}[\mathrm{i}+1]-\mathrm{MappedPivot}[\mathrm{i}]}{\mathrm{InputPivot}[\mathrm{i}+1]-\mathrm{InputPivot}[\mathrm{i}]}\ast (Y_{pred}-\mathrm{InputPivot}[\mathrm{i}])+\mathrm{MappedPivot}[\mathrm{i}]$
实现:查找表(LUT,look-up-table)与即时计算
LUT
计算并预先存储FwdMapLUT和InvMapLUT以在Tile级别使用,并且向前和反向映射可以简单地应用查表操作,实现为:
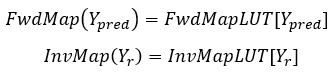
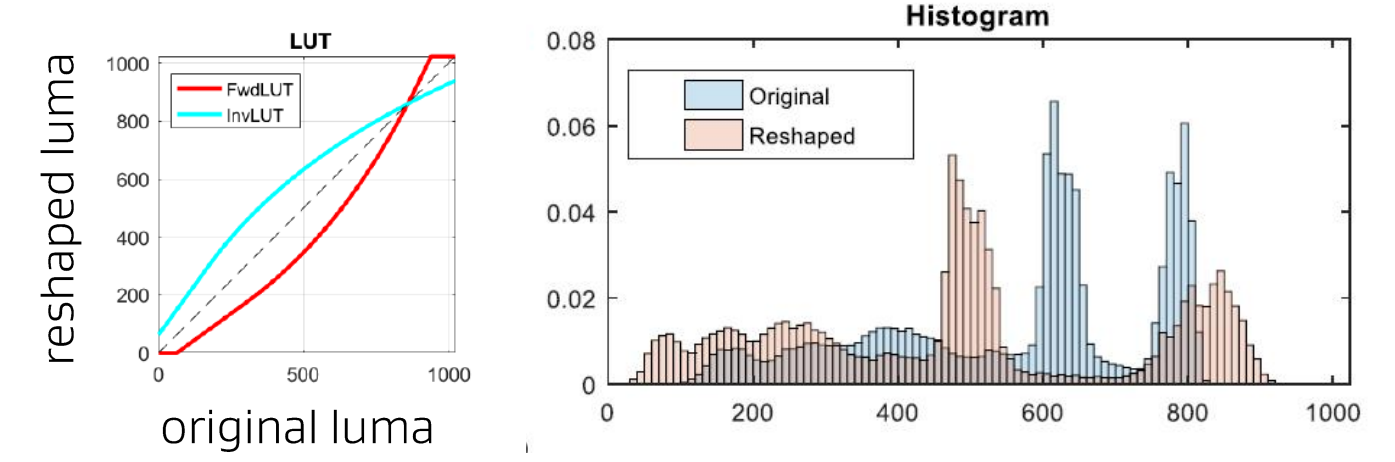
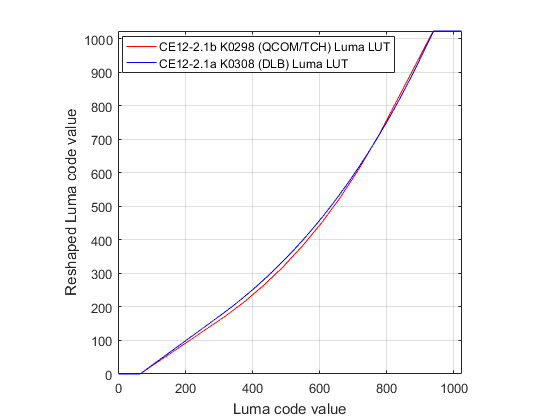
下图为查找表的例子:
CE12-2.1a: dQP模型产生的固定映射函数
CE12-2.1b: a piece-wise linear (PWL) model
即时计算
$Y_{pred}^{\prime}=\frac{\mathrm{MappedPivot}[\mathrm{i}+1]-\mathrm{MappedPivot}[\mathrm{i}]}{\mathrm{InputPivot}[\mathrm{i}+1]-\mathrm{InputPivot}[\mathrm{i}]}\ast (Y_{pred}-\mathrm{InputPivot}[\mathrm{i}])+\mathrm{MappedPivot}[\mathrm{i}]$
正向:像素值要右移 6 位得到所属区间 i。然后检索该段的线性模型参数并即时应用以计算映射的亮度值。
反向:在映射域每段大小不同,因此反变换时需要较为复杂的计算来得出某个值属于哪个区域,从而增加了解码复杂度。VVC采取了以下限制,假设映射域范围时0-1023,首先范围被分为32等份,如果$MappedPivot[ i ]$不是32的倍数,$MappedPivot[ i + 1 ]$和$MappedPivot[ i ]$不能属于同一个32等分段(也就是说$MappedPivot[ i + 1 ]$必须增加大于等于32的值)。这样可以使用右移5位来判断数值属于哪一段。InvMap函数也可以使用简单的右移5位来执行。
CS
CS 在色度块级进行操作,在 VVC 中,色度的 QP 依赖于对应亮度的 QP, 当使用 LM 之后映射域的亮度值和原始信号域的亮度值可能不同,所以对应色度 QP 可能不是最优的,LMCS 中通过依赖亮度值的色度缩放解决这个问题。
如果当前块使用了亮度映射,且dual tree parittion 关闭,则需要额外的标志标明是否使用色度残差尺度伸缩。如果当前快没有使用亮度映射,或者dual tree parittion打开(即亮度、色度单独划分预测),色度残差尺度伸缩默认关闭。另外区域小于等于4的色度块不适用CS。
解码端CS步骤
- 对解码出的chroma残差进行反量化反变换产生【映射域】的色度残差$C_{resScale}$
- $C_{res} = C_{resScale} * invScaleC$
- $C_{r} = C_{res} + C_{pred}$
各分段内部$invScaleC$值是相同的。为了减少流水线延迟,$invScaleC$取决于当前虚拟流水线数据单元VPDU左方上方的重建亮度平均值$avgY’$
1、利用亮度映射的$InvMap$函数,找出$avg Y′$ 所对应分段线性模型的段序号$Y_{idx}$
2、$invScaleC = cScaleInv[ Y_{idx} ]$, $cScaleInv[] $为事先定义好的表$LUT$
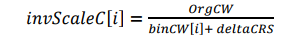
如果当前CU时inter 128x128, inter 128x64或inter 64x128,第一个VPDU的CS缩放因子被用于所有色度变换块。对于整个色度块,$invScaleC$是一个固定值。
deltaCRS:cfg中指定,APS中传输
LMCSOffset : 2 # chroma residual scaling offset
syntax
LMCS可以在序列级、图片级或slice级进行控制。相关参数在APS中编码, aps_parameter_type = 1(LMCS_APS)。每个视频序列可以使用4个LMCS APS,每帧只能使用一个LMCS APS。LMCS APS数据包含两部分:1)与最多16段的线性模型有关的语法;2)CS偏移值deltaCRS,如果视频信号不是单色的。
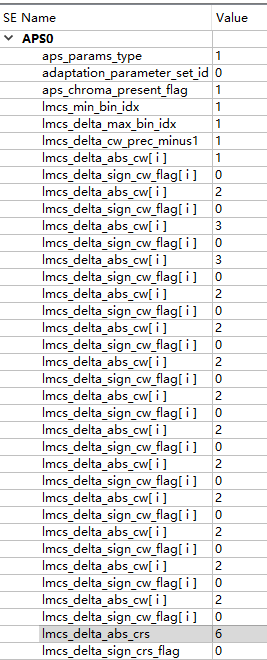
lmcs_min_bin_idx:指定 LMCS 中分段模型的最小分段的索引号,其值在 [0,15]之间。
lmcs_delta_max_bin_idx:该值等于 15-LmcsMaxBinIdx,其中 LmcsMaxBinIdx 是 LMCS 中分段模型的最大分段的索引号。
aps_chroma_Present_Flag:表示是否使用deltaCRS
lmcs_delta_cw_prec_minus1:该值加 1 代表表示 lmcs_delta_abs_cw[ i ]所用 的比特数,其值在[0,14]之间。
lmcs_delta_abs_cw[ i ]:表示第 i 个分段的码字数量增量的绝对值。
lmcs_delta_sign_cw_flag[ i ] : 表 示 lmcsDeltaCW[ i ] 的 符 号 , 如 果 lmcs_delta_sign_cw_flag[ i ]等于 0 则 lmcsDeltaCW[ i ]为正,否则为负。
lmcs_delta_abs_crs:表示 lmcsDeltaCrs 的绝对值。
lmcs_delta_sign_crs_flag:表示 lmcsDeltaCrs 的符号。
编码端参数估计
两种算法,分别对应SDR/HDR HLG视频和HDR PQ视频。
对SDR/HDR HLG视频
针对PSNR进行优化,将更多的luma码字分配给空间平滑区域而不是非平滑区域

1. 初始化时为每个有效分段分配相同数量的码字。
- 对于不是10bit的信号归一化到10bit。
将码字范围[0,1023]均匀划分为16个分段。
确定有效分段数量,有效指的是该分段中大部分亮度值在图像中出现了。例如,对于10bit窄范围信号,[0,63]和[941,1023]无法取到,则第0和15个分段是无效的,一共有14个有效分段。
对每个有效分段按下面方式分配相同数量的码字。
$binCW[i]=round\left(\frac{totalCW}{endIdx-startIdx+1}\right)$$binCW[i]$是分配给第i段的码字数量,$totalCW$是允许的码字总数,$startIdx$和$endIdx$分别是第一个和最后一个有效片的索引值。
2. 基于图像统计结果调整码字数量。
- 对于图像中的每个亮度像素,计算以其为中心$winSize$ x $winSize$邻域内的空域方差$pxlVar$。其中$winSize=Floor(min(width,height)/240)-2+1$。$width,height$是图像宽高。
对于16个分段,计算每个的$pxlVar$平均值,$binCnt[i]$是第i个分段样本数。
$binVar[i]=\frac{\sum_{bin}\log_{10}(pxlVar+1.0)}{binCnt[i]}$计算所有分段$binVar$的均值$meanVar$,和每个分段对应的归一化值$normVar[i]=binVar[i]/ meanVar$。
- 调整码字,将更多码字分配给$normVar$小的分段
$\quad \mathrm{if}\ normVar[i]< 1.0, \ binCW [i]=\begin{cases} binCW\ [i]+delta1[i],\quad 0.8\leq normVar[i] < 0.9\\ binCW\ [i]+delta2[i],\qquad normVar\ < 0.8 \end{cases}$
$else\ if\ normVar [i] > 1.0, binCW[i]=\begin{cases} binCW[i]-delta1 [i],\quad 1.1 < normVar[i]\leq 1.2\\ binCW [i]-delta2[i],\qquad normVar[i]\ > 1.2 \end{cases} $
$ delta1[i]= round*(10∗hisr[i]) $and $delta2 [i]=round(20∗hisr[i])$
$hist[i]$是第$i$个分段样本数相对于所有像素数的百分比,clip到[0,0.4],避免过度的码字分配。
3、调整码字数量到最大码字数量。
如果分配的码字数量超过允许的最大数量,从第一分段开始,逐渐减少分配给每个分段的码字数,直到分配的码字总数等于允许的码字总数。
4、设置rate、slice和色度自适应参数。
- 当编码使用的QP较小(<=22)时允许使用rate adaptation以保留更多图像细节。当开启rate adaptation应且有效分段数量小于16时,分配给每个分段的码字数量为66。
- slice自适应使得上面步骤2、3只能在IRAP图像上进行。可以根据以下选项对slice进行LMCS激活:1)对所有帧内和子序列帧间slices;2)仅对TemporalID=0的子序列的图像的slices;3)仅对子序列帧间slices。对某些视频,其映射域图像的平均方差会大于原始像素域平均方差,且差值超过预定义阈值,此时对帧内slices禁用LMCS压缩效果会更好,或者仅对TemporalID=0的图像的slices使用LMCS。
- 色度自适应可以根据图像亮度和色度分量的相对平均空域方差决定是否使用色度残差的缩放。如果色度分量和亮度分量的平均空域方差比值超过预定义阈值则不进行色度残差的缩放。
对HDR PQ视频
优化加权PSNR(wPSNR),luma映射曲线是直接基于wPSNR中使用的权重得出
本示例针对HDR PQ内容提供了一个固定的映射函数,该函数通过luma dQP( luma-dependent quantization adaptation method)建模。luma dQP基于平均亮度值为每个CTU生成局部delta QP(dQP)。
$\mathrm{dQP}(avgY)=max(-3,min(6,0.015\ast avgY-1.5-6))$
HDR PQ视频使用wPSNR作为客观评价指标,wPSNR通过wSSE(ܻY)计算得到,
$\mathrm{wSSE}(\mathrm{Y})=2^{\wedge}(dQP(Y)/3)$
HDR PQ的LMCS映射函数通过下面步骤得到:
1、计算映射曲线的斜率
$slope[Y]=\mathrm{sqrt}(\mathrm{wSSE}(Y))=2^{\wedge}(dQP(Y)/6)$
如果信号是窄范围,对于10bit视频的Y值取值为[0,63]和[940,1023]时斜率设为0。
2、对映射函数斜率积分。Y=0,1…maxY-1,
$F[Y+1]=F[Y]+slope[Y]$
3、通过将F[Y]归一化到[0,maxY]得到look-up table,FwdLUT[Y]
$FwdLUT[Y]=\mathrm{clip}3 (0, \mathrm{maxY}, \mathrm{round}(F[Y]\ast maxY/F[maxY]))$
4、计算每个分段码字数量
$binCW[15]=FwdLUT[1023]-FwdLUT[960]$
$for\ i = 14;i >=0; i—$
$binCW[i]=FwdLUT[(i+1)\ast OrgCW]-FwdLUT[i\ast OrgCW]$
代码